In this section we present the meta data schema of hermes and provide an example of how to load datasets from text files.
Metadata Schema
Here is an overview of the Hermes Metadata Schema:
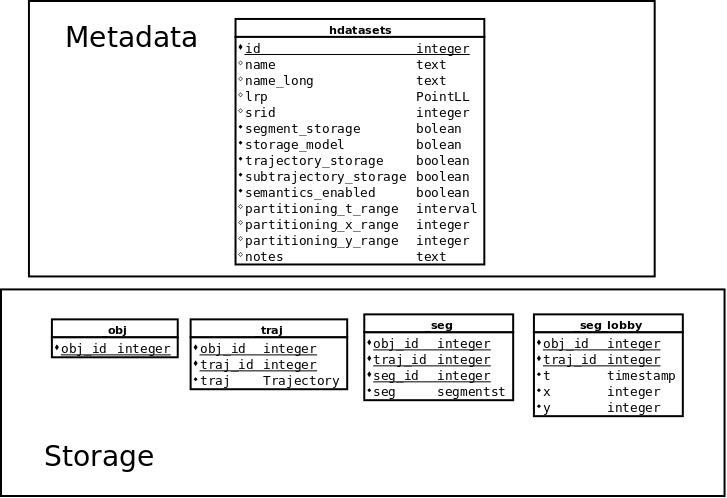
Hermes Metadata Schema
hdataset table
This section describes the structure of the database that was designed to be able to host multiple datasets. That metadata infrastructure takes the form of a table named hdataset. The structure of the hdataset table is as follows [vodas2013hermes] :
- id is an auto incremented integer column that is the primary key of the table. Each dataset hosted is given an id.
- name is a text column that contains a unique short name of the dataset.
- name_long is a text column that contains a human friendly name of the dataset.
- lrp is a PointLL column that is the reference point for coordinate transformation.
- srid is an integer column that contains the EPSG code of the projected reference system in which the dataset is stored in Hermes. Note that if we give a value for local ref poi then SRID will have to be NULL and vice versa.
- segment_storage a boolean value that shows whether the segment storage is in use
- trajectory_storage a boolean value shows whether the trajectory storage is in use
- subtrajectory_storage is not currently in use
- semantics_enabled is not currently in use
- partitioning_t_range is not currently in use
- partitioning_x_range is not currently in use
- partitioning_y_range is not currently in use
- notes is a text column that contains arbitrary notes on the dataset.
Each dataset in this table has a unique identifier and a unique short name e.g. [1, ‘imis’] or [2, ‘milan’]. Most spatio-temporal datasets are in the form of [objectID, trajectoryID, t, lon, lat] where “objectID” is the identifier of the object, “trajectoryID” is the identifier of the trajectory for that object, “t” is the UTC (Coordinated Universal Time) timestamp at which it was recorded and “lon” and “lat” are degrees of longitude and latitude in WGS 84 Geographic Coordinate System. “objectID” and “trajectoryID”, normally, are combined to form the unique identifier of a trajectory in a specific dataset [vodas2013hermes]
Each dataset consists of three tables. Each table’s name begins with the dataset’s name followed by a suffix [vodas2013hermes] :
- _obj: this table hosts the objects that exist in the dataset and contains one column:
- obj_id the unique identifier of the object.
- _traj: this table hosts the trajectories of the objects and contains three columns:
- obj_id is a foreign key to obj table.
- traj_id is an identifier for the particular trajectory of the object.
- traj contains an object of type Trajectory (optional).
- _seg: this table will host the segments of the trajectories and contains four columns:
- obj_id is a foreign key to obj table.
- traj_id is a foreign key to traj table.
- seg_id is an identifier for the particular segment of the trajectory.
- seg contains a segment of a trajectory, an object on type SegmentST.
- _seg_lobby: this table is not currently in use
- obj_id is not currently in use
- traj_id is not currently in use
- t is not currently in use
- x is not currently in use
- y is not currently in use
According to [vodas2013hermes] the objects table and the trajectories table must have data in contrast with segments table. The “traj” column in trajectories table could be empty if trajectories are stored in the segments table. It is always possible to build a trajectory object from its corresponding segments that we can find in the segments table on the fly using aggregate functions. That allows us to use advanced methods that Hermes provides for its “Trajectory” type.
hparameters table
Finally there is an hparameters table, with global parameters visible by all tables/function and the structure of the table is a (key,value) format.
- key value contains a text
- value value contains a text
hdataset_statistics table
The statistics for each dataset are stored in the table hdatasets_statistics. The statistics about the dataset that can be kept in this table are:
- bounds of the dataset (tmin, tmax, lx, ly, hx, hy, llon, llat, hlon, hlat).
- centroid of the dataset (centroid x, centroid y, centroid lon, centroid lat).
- number of objects / trajectories / points / segments.
- minimum /average / maximum number of points per trajectory / trajectory duration / trajectory length.
The structure of the table is described below:
- dataset is a foreign key to hdatasets table storing the primary key of the dataset.
- nr_objects is a bigint storing the total number of objects stored in the table _obj of the dataset.
- nr_trajectories is a bigint storing the total number of Trajectories in the table _traj of the dataset.
- nr_segments is a bigint storing the total number of Segments in the table _seg of the dataset.
- nr_points is a bigint storing the total number of Points in the Trajectories.
- tmin is a timestamp showing the minimum timestamp of the dataset
- tmax is a timestamp showing the maximum timestamp of the dataset
- lx is an integer returning the lowest x coordinate
- ly is an integer returning the lowest y coordinate
- hx is an integer returning the highest x coordinate
- hy is an integer returning the highest y coordinate
- llon is a double precision number returning the lowest longitude
- llat is a double precision number returning the lowest latitude
- hlon is a double precision number returning the highest longitude
- hlat is a double precision number returning the highest latitude
- points_centroid_t is a timestamp showing the centroid of the dataset
- points_centroid_x is an integer showing the centroid of the x coordinate in the dataset
- points_centroid_y is an integer showing the centroid of the y coordinate in the dataset
- points_centroid_lon is a double precision number showing the centroid of the longitude in the dataset
- points_centroid_lat is a double precision number the centroid of the latitude in the dataset
- trajectories_centroid_t is a timestamp showing the centroid of the trajectories of the dataset
- trajectories_centroid_x is an integer showing the centroid of x coordinates of the trajectories of the dataset
- trajectories_centroid_y is an integer showing the centroid of y coordinates of the trajectories of the dataset
- trajectories_centroid_lon is a double precision number showing the centroid of longitude coordinates of the trajectories of the dataset
- trajectories_centroid_lat is a double precision number the centroid of latitude coordinates of the trajectories of the dataset
- duration is an interval showing the duration of the dataset
- area is a bigint showing the area of the dataset
- normalized_sampling_rate is a double precision number showing the normalized sampling rate
- min_object_trajectories is a bigint showing the minimum number of ojbects per trajectory in _traj table
- max_object_trajectories is a bigint showing the maximum number of ojbects per trajectory in _traj table
- avg_object_trajectories is a double precision number showing the average number of ojbects per trajectory in _traj table
- stddev_object_trajectories is a double precision number showing the standard deviation of ojbects per trajectory in _traj table
- median_object_trajectories is a double precision number showing the median number of ojbects per trajectory in _traj table
- min_object_normalized_sampling_rate is a bigint showing the minumum normalized number of ojbects per trajectory in _traj table
- max_object_normalized_sampling_rate is a bigint showing the maximum normalized number of of ojbects per trajectory in _traj table
- avg_object_normalized_sampling_rate is a double precision number showing the average normalized number of ojbects per trajectory in _traj table
- stddev_object_normalized_sampling_rate is a double precision number showing the standard deviation of ojbects per trajectory in _traj table
- median_object_normalized_sampling_rate is a double precision number showing the median normalized number of ojbects per trajectory in _traj table
- min_trajectory_points is a bigint number showing the minimum number of points in a trajectory in _traj table
- max_trajectory_points is a bigint number showing the maximum number of points in a trajectory in _traj table
- avg_trajectory_points is a double precision number number showing the average number of points in a trajectory in _traj table
- stddev_trajectory_points is a double precision number number showing the standard deviation of points in a trajectory in _traj table
- median_trajectory_points is a double precision number number showing the median number of points in a trajectory in _traj table
- min_trajectory_duration is an interval showing the minimum duration of a trajectory in _traj table
- max_trajectory_duration is an interval showing the maximum duration of a trajectory in _traj table
- avg_trajectory_duration is an interval showing the average duration of a trajectory in _traj table
- stddev_trajectory_duration is an interval showing the standard deviation of durations of trajectories in _traj table
- median_trajectory_duration is an interval showing the median duration of a trajectory in _traj table
- min_trajectory_length is a double precision number showing the minimum length of a trajectory in _traj table
- max_trajectory_length is a double precision number showing the maximum length of a trajectory in _traj table
- avg_trajectory_length is a double precision number showing the average length of a trajectory in _traj table
- stddev_trajectory_length is a double precision number showing the standard deviation of lengths of trajectories in _traj table
- median_trajectory_length is a double precision number showing the median length of trajectories in _traj table
- min_trajectory_displacement is a double precision number showing the minimum displacement of trajectories in _traj table
- max_trajectory_displacement is a double precision number showing the maximum displacement of trajectories in _traj table
- avg_trajectory_displacement is a double precision number showing the average displacement of trajectories in _traj table
- stddev_trajectory_displacement is a double precision number showing the standard deviation of displacements of trajectories in _traj table
- median_trajectory_displacement is a double precision number showing the median displacement of trajectories in _traj table
- min_trajectory_area is a bigint showing the minimum area of trajectories in _traj table
- max_trajectory_area is a bigint showing the maximum area of trajectories in _traj table
- avg_trajectory_area is a double precision number showing the average area of trajectories in _traj table
- sttdev_trajectory_area is a double precision number showing the standard deviation of area of trajectories in _traj table
- median_trajectory_area is a double precision number showing the median area of trajectories in _traj table
- min_trajectory_gyradius is a double precision number showing the minimum gyradius of trajectories in _traj table
- max_trajectory_gyradius is a double precision number showing the maximum gyradius of trajectories in _traj table
- avg_trajectory_gyradius is a double precision number showing the average gyradius of trajectories in _traj table
- stddev_trajectory_gyradius is a double precision number showing the standard deviation of gyradius of trajectories in _traj table
- median_trajectory_gyradius is a double precision number showing the median gyradius of trajectories in _traj table
- min_trajectory_angle_xx_avg is a double precision number showing the minimum average direction of trajectories in _traj table
- max_trajectory_angle_xx_avg is a double precision number showing the maximum average direction of trajectories in _traj table
- avg_trajectory_angle_xx_avg is a double precision number showing the average average direction of trajectories in _traj table
- stddev_trajectory_angle_xx_avg is a double precision number showing the standard deviation of average directions of trajectories in _traj table
- median_trajectory_angle_xx_avg is a double precision number showing the median average direction of trajectories in _traj table
- min_trajectory_average_speed is a double precision number showing the minimum average speed of a trajectory in _traj table
- max_trajectory_average_speed is a double precision number showing the maximum average speed of a trajectory in _traj table
- avg_trajectory_average_speed is a double precision number showing the average of the average speed of trajectories in _traj table
- stddev_trajectory_average_speed is a double precision number showing the standard deviation of average speeds of trajectories in _traj table
- median_trajectory_average_speed is a double precision number showing the median average speed of trajectories in _traj table
- min_trajectory_normalized_sampling_rate is a double precision number showing the minumum normalized sampling rate of trajectories in _traj table
- max_trajectory_normalized_sampling_rate is a double precision number showing the maximum normalized sampling rate of trajectories in _traj table
- avg_trajectory_normalized_sampling_rate is a double precision number showing the average normalized sampling rate of trajectories in _traj table
- stddev_trajectory_normalized_sampling_rate is a double precision number showing the standard deviation of the normalized sampling rate of the trajectories in _traj table
- median_trajectory_normalized_sampling_rate is a double precision number showing the median normalized sampling rate of trajectories in _traj table
- min_segment_duration is an interval showing the minumum duration of the segments in _seg table
- max_segment_duration is an interval showing the maximum duration of the segments in _seg table
- avg_segment_duration is an interval showing the average duration of the segments in _seg table
- stddev_segment_duration is an interval showing the standard deviation of durations of the segments in _seg table
- median_segment_duration is an interval showing the median duration of the segments in _seg table
- min_segment_length is a double precision number showing the minumum length of the segments in _seg table
- max_segment_length is a double precision number showing the maximum length of the segments in _seg table
- avg_segment_length is a double precision number showing the average length of the segments in _seg table
- stddev_segment_length is a double precision number showing the standard deviation of the lengths of the segments in _seg table
- median_segment_length is a double precision number showing the median length of the segments in _seg table
- min_segment_area is a double precision number showing the minumum area of the segments in _seg table
- max_segment_area is a double precision number showing the maximum area of the segments in _seg table
- avg_segment_area is a double precision number showing the average area of the segments in _seg table
- stddev_segment_area is a double precision number showing the standard deviation of areas of the segments in _seg table
- median_segment_area is a double precision number showing the median area of the segments in _seg table
- min_segment_angle_xx is a double precision number showing the minimum average direction of of the segments in _seg table
- max_segment_angle_xx is a double precision number showing the maximum average direction of of the segments in _seg table
- avg_segment_angle_xx is a double precision number showing the average average direction of of the segments in _seg table
- stddev_segment_angle_xx is a double precision number showing the standard deviation of the average directions of of the segments in _seg table
- median_segment_angle_xx is a double precision numbers howing the median average direction of of the segments in _seg table
- min_segment_average_speed is a double precision number showing the minimum average speed of the segments in _seg table
- max_segment_average_speed is a double precision number showing the maximum average speed of the segments in _seg table
- avg_segment_average_speed is a double precision number showing the average average speed of the segments in _seg table
- stddev_segment_average_speed is a double precision number showing the standard deviation of the averages speed of the segments in _seg table
- median_segment_average_speed is a double precision number showing the median average speed of the segments in _seg table
Example Dataset
Loading Dataset
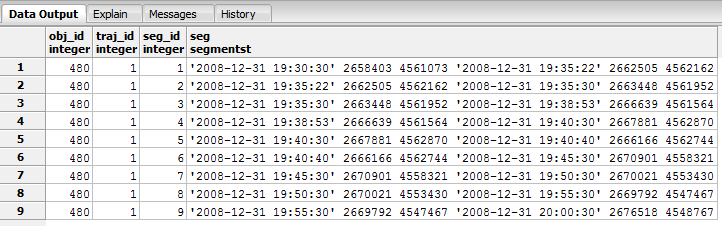
In these pages you will find some examples of the Hermes MOD. These examples use the IMIS3days Dataset, which has been kindly provided by the IMIS HELLAS. According to [pelekis2014mobility] the dataset covers almost 3 days of informations about ships sailing at Greek Seas. The “IMIS 3 Days” dataset spawns from “2008-12-31 19:29:30” to “2009-01-02 17:10:06” and contains positions reports for 933 ships. It is spatially constrained in the Aegean Sea and covers an area of 496736 km 2 , from (21,35)-lowest to (29,39)-highest longitude-latitude point [vodas2013hermes] .
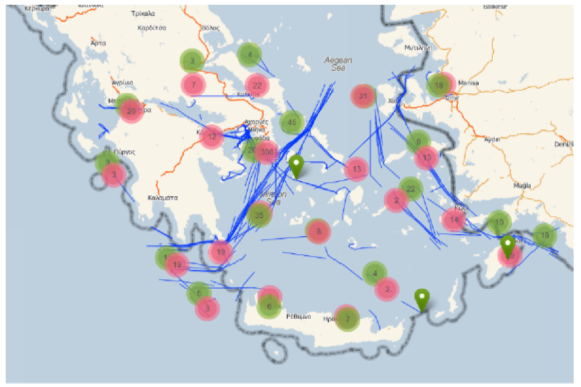
Overview of the IMIS 3 Days dataset
Loading the dataset into Hermes MOD is simple, due to a module called "Hermes-Loader", which automates the creation and feeding of the respective database table as well as the transformation of coordinates from degrees (lon/lat to meters (x/y)
[pelekis2014mobility.]
Before loading the AIS data in PostgreSql, one needs to save the data files in the PostgreSQL directory in a file type of csv with a header for column names with the following structure: <obj_id, traj_id, t, lon, lat>. You can find the directory by executing the below command in the database:
postgres=# SHOW data_directory;
data_directory
------------------------------
/var/lib/postgresql/9.4/main
(1 row)
Afterwards copying the imis3days.txt file in the database directory the below commands must be executed:
SELECT HLoader('imis', 'IMIS 3 Days');
SELECT HLoaderCSV_II('imis', 'imis3days.txt');
SELECT HDatasetsOfflineStatistics('imis');
CREATE INDEX ON imis_seg USING gist (seg) WITH (FILLFACTOR = 100);
In the above script the first and the second line create the tables that will host the dataset and fill these tables, respectively, with the data that are found in file “imis3days.txt”, according to the formatting discussed above. The function HLoader loads the dataset by taking into account the information / parameters that we pass to the function but also the ones that are present in the table. Because loader can be extended to support more formats beyond CSV this is why “HLoader” table exists to hold the specific parameters for that extension. Every loader though must have the parameters that are passed in the function since they are common to any dataset and loader combination [vodas2013hermes.]
postgres=# SELECT HLoader('imis', 'imis3days');
hloader
---------
(1 row)
postgres=# \dt
List of relations
Schema | Name | Type | Owner
--------+----------------------+-------+----------
public | hdatasets | table | postgres
public | hdatasets_statistics | table | postgres
public | hparameters | table | postgres
public | imis_obj | table | postgres
public | imis_seg | table | postgres
public | imis_seg_lobby | table | postgres
public | imis_traj | table | postgres
(7 rows)
If we want to enable and the trajectory storage model instead of the above command we should use the below command.
SELECT hdatasetsregister('imis', 'imis', dataset_trajectory_storage:=TRUE, dataset_segment_storage:=TRUE);
hdatasetsregister
-------------------
t
(1 row)
<<<<<<< HEAD
This command enables both the trajectory and segment storage. By default only the segment storage is enabled.
In the execution of the second line there might be some warning but there is no reason for worrying
This command enables both the trajectory and segment storage. By default only the segment storage is enabled.
In the execution of the second line there might be some warning but there is no reason for worrying (ask marios for more informations)
develop
postgres=# SELECT HLoaderCSV_II('imis', 'imis3days.txt');
NOTICE: table "imis_input_data" does not exist, skipping
CONTEXT: SQL statement "DROP TABLE IF EXISTS imis_input_data CASCADE;"
PL/pgSQL function hdatasetsload(text,text,boolean) line 57 at EXECUTE statement
SQL statement "SELECT HDatasetsLoad(dataset_name, csv_file)"
PL/pgSQL function hloadercsv_ii(text,text) line 3 at PERFORM
hloadercsv_ii
---------------
(1 row)
Line 4 calculates some statistics for the dataset, such as average number of points per trajectory, average duration of trajectories, and average length of trajectories (see also hdataset_statistics table).
postgres=# SELECT HDatasetsOfflineStatistics('imis');
hdatasetsofflinestatistics
----------------------------
(1 row)
After the calculation of the statistics we can see the statistics with simple queries such as:
SELECT *
FROM hdatasets_statistics
WHERE dataset = HDatasetID('imis');
Line 4 creates an index of type 3D R-tree on the dataset.
postgres=# CREATE INDEX ON imis_seg USING gist (seg) WITH (FILLFACTOR = 100);
CREATE INDEX
By default, the dataset is hosted in "imis_seg" table, according to a segment-oriente storage model. The list of attributes of “imis_seg” is as follows: <obj_id, traj_id, seg_id, seg>, where obj_id corresponds to object’s identifier (in our case, the MMSI of the ship), traj_id corresponds to a unique identifier of object’s trajectory, seg_id corresponds to a unique identifier object’s trajectory segment, and seg is the geometry of the trajectory segment, of type SegmentST [pelekis2014mobility.]
New loader
A new way of uploading a new dataset to Hermes is the use of the wrapper function load_dataset. The signature is:
SELECT load_dataset(name text, description text, file text, trajectory_storage boolean)
So, if we wanted to upload the imis dataset, instead of running the previous four commands we run:
SELECT load_dataset('imis', 'IMIS 3 Days', 'imis3days.txt', False);
or, the above with the last parameter set to True, if we wanted both the trajectory storage and segment storage modes enabled.
Deleting Dataset
If someone wants to delete the dataset, he should execute the below command:
SELECT HDatasetsDrop('imis');
- See also
- Catalog.sql
-
Compatibility.sql
-
Loader.sql
-
Statistics.sql <<<<<<< HEAD
Transformations
Hermes provides a way to perform a series of transformations upon a dataset stored in the engine.
With the functions provided, the user can easily get new datasets, based on the initial one. The user has the options of save the generated datasets to the engine, export them to a csv file, or both.
Each one of the six different transformation functions is further described below, followed by a hands on example.
Decreased Sampling Rate Transformation
trajectory_transformation_dec_sr (dataset, rate[, save [, new_dataset_name[, csv_file]]])
Returns
The integer 1 to indicate that everything went right.
Parameters Description
- dataset Text, the name with which the dataset is stored in Hermes.
- rate Float between 0 and 1, number of points to be deleted (rate * |points|).
- save (Optional) Boolean, indicates whether the new dataset will be saved in Hermes or not. If left blank, the new dataset will be saved.
- new_dataset_name (Optional) Text, If save is True, the name of the new dataset inside Hermes. If left blank, the name of the new_dataset will be transformed_dec_sr
- csv_file (Optional) Boolean, Indicates whether the new dataset will be exported to a csv file, with the default format of Hermes. If left blank, the dataset will be exported to a csv file.
Example
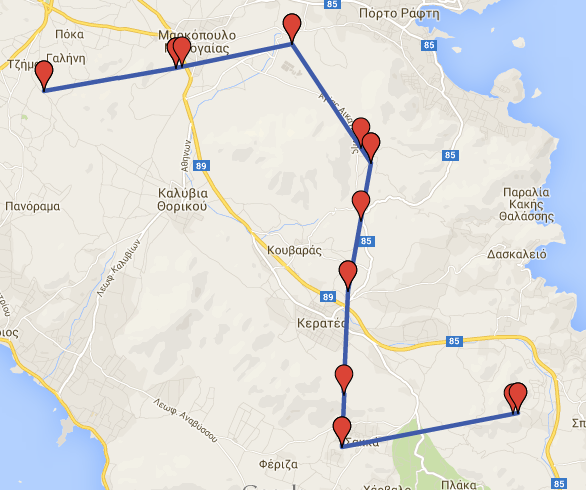
For example purposes, suppose we have a dataset, saved in Hermes, containing one trajectory. The name of the dataset is gmaps. The segments of the dataset are shown below.
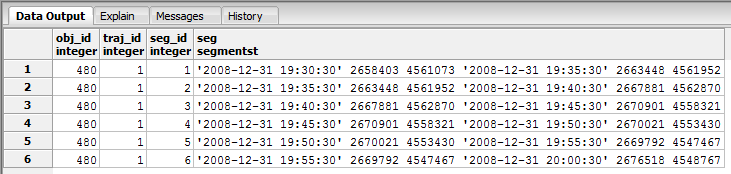
Segments of gmaps dataset
It is clear that the trajectory consists of 7 ST Points. If we wanted to perform a decreased sampling rate transformation by keeping 60% of the initial points, we could run the following querie:
SELECT trajectory_transformation_dec_sr('gmaps', 0.4, True, 'new_d', True);
As a result, we get a new dataset named new_d_dec_sr, which consists of random 60% of the initial points. If we run the following querie we get the new trajectory segments:
SELECT * FROM new_d_dec_sr_seg;

Segments of decreased sr gmaps dataset
Additionally, due to csv_file parameter being True, we get a cvs file in the data folder. The name of the file would be gmaps_transformed_decsr_0.6.txt. Generally, the name of the csv file will be dataset + _transformed + _kind of transformation + _parameters
If we load the initial and the transformed datasets in Google Maps (from the csv files), we get the following result:
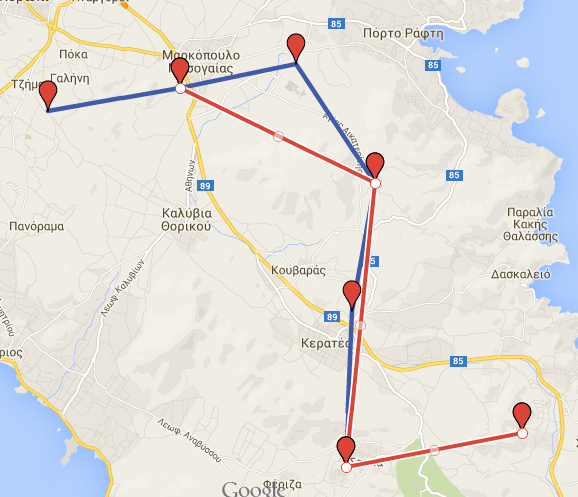
Initial \(blue\) and transformed \(red\) dataset
Increased Sampling Rate Transformation
trajectory_transformation_inc_sr (dataset, rate[, save [, new_dataset_name[, csv_file]]])
Returns
The integer 1 to indicate that everything went right.
Parameters Description
- dataset Text, the name with which the dataset is stored in Hermes.
- rate Float between 0 and 1, number of points to be added (rate * |points|).
- save (Optional) Boolean, indicates whether the new dataset will be saved in Hermes or not. If left blank, the new dataset will be saved.
- new_dataset_name (Optional) Text, If save is True, the name of the new dataset inside Hermes. If left blank, the name of the new_dataset will be transformed_inc_sr
- csv_file (Optional) Boolean, Indicates whether the new dataset will be exported to a csv file, with the default format of Hermes. If left blank, the dataset will be exported to a csv file.
Example
For example purposes, suppose we have a dataset, saved in Hermes, containing one trajectory. The name of the dataset is gmaps. The segments of the dataset are shown below.
Segments of gmaps dataset
It is clear that the trajectory consists of 7 ST Points. If we wanted to perform an increased sampling rate transformation by adding 60% more points, we could run the following querie:
SELECT trajectory_transformation_inc_sr('gmaps', 0.6, True, 'new_i', True);
Because we perform increased sampling rate transformation all the new points will be on the initial trajectory. In order to achive this, atInstant function is used internally. As a result, we get a new dataset named new_i_dec_sr, which consists of random 60% more points. If we run the following querie we get the new trajectory segments:
SELECT * FROM new_i_inc_sr_seg;
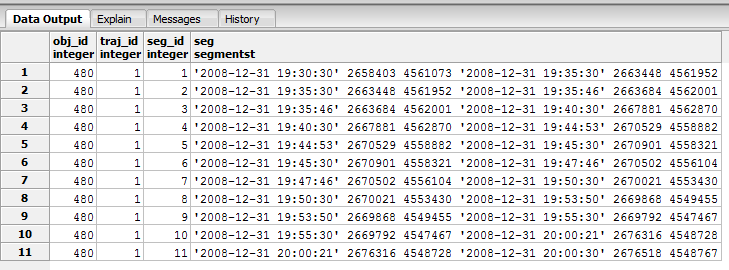
Segments of increased sr gmaps dataset
Additionally, due to csv_file parameter being True, we get a cvs file in the data folder. The name of the file would be gmaps_transformed_incsr_0.6.txt. Generally, the name of the csv file will be dataset + _transformed + _kind of transformation + _parameters
If we load the initial and the transformed datasets in Google Maps (from the csv files), we get the following result:
Initial \(blue\) and transformed dataset
Time Interval With Step Transformation
trajectory_transformation_inc_sr (dataset, start_date, end_date, step[, save [, new_dataset_name[, csv_file]]])
Returns
The integer 1 to indicate that everything went right.
Parameters Description
- dataset Text, the name with which the dataset is stored in Hermes.
- start_date Text, a timestamp with the following format: yyyy-mm-dd hh:mm:ss. Indicates the start of the time interval
- end_date Text, a timestamp with the following format: yyyy-mm-dd hh:mm:ss. Indicates the end of the time interval
- step Integer, indicates the step inside time interval, measured in seconds.
- save (Optional) Boolean, indicates whether the new dataset will be saved in Hermes or not. If left blank, the new dataset will be saved.
- new_dataset_name (Optional) Text, If save is True, the name of the new dataset inside Hermes. If left blank, the name of the new_dataset will be transformed_time_sr
- csv_file (Optional) Boolean, Indicates whether the new dataset will be exported to a csv file, with the default format of Hermes. If left blank, the dataset will be exported to a csv file.
Example
For example purposes, suppose we have a dataset, saved in Hermes, containing one trajectory. The name of the dataset is gmaps. The segments of the dataset are shown below.
Segments of gmaps dataset
It is clear that the trajectory consists of 7 ST Points. If we wanted to keep just the points between 2008-12-31 19:30:30 and 2008-12-31 19:50:30, every 10 minutes we could run the following querie:
SELECT trajectory_transformation_time_sr('gmaps', '2008-12-31 19:30:30', '2008-12-31 19:50:30', 600, True, 'new_t', True);
As a result, we get a new dataset named new_t_time_sr, which consists of all the points (if there are any) between the indicated interval in combination with the given step. If we run the following querie we get the new trajectory segments:
SELECT * FROM new_t_time_sr_seg;

Segments of time sr gmaps dataset
Additionally, due to csv_file parameter being True, we get a cvs file in the data folder. The name of the file would be gmaps_transformed__timesr__2008-12-31 19_30_30__2008-12-31 19_50_30__600. Generally, the name of the csv file will be dataset + _transformed + _kind of transformation + _parameters
If we load the initial and the transformed datasets in Google Maps (from the csv files), we get the following result:
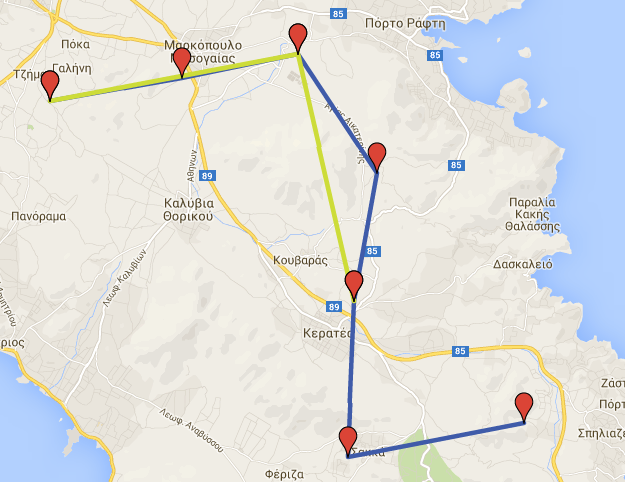
Initial \(blue\) and transformed \(green\) dataset
Adding Noise Points Transformation
trajectory_transformation_add_noise (dataset, rate, distance[, save [, new_dataset_name[, csv_file]]])
Returns
The integer 1 to indicate that everything went right.
Parameters Description
- dataset Text, the name with which the dataset is stored in Hermes.
- rate Float between 0 and 1, number of points to be added (rate * |points|).
- distance Integer, outlier - trajectory maximum distance, in meters.
- save (Optional) Boolean, indicates whether the new dataset will be saved in Hermes or not. If left blank, the new dataset will be saved.
- new_dataset_name (Optional) Text, If save is True, the name of the new dataset inside Hermes. If left blank, the name of the new_dataset will be transformed_add_noise
- csv_file (Optional) Boolean, Indicates whether the new dataset will be exported to a csv file, with the default format of Hermes. If left blank, the dataset will be exported to a csv file.
Example
For example purposes, suppose we have a dataset, saved in Hermes, containing one trajectory. The name of the dataset is gmaps. The segments of the dataset are shown below.
Segments of gmaps dataset
It is clear that the trajectory consists of 7 ST Points. If we wanted to add 40% more noise points, each one of them would be 2 km, at most, apart from the trajectory, we could run the following querie:
SELECT trajectory_transformation_add_noise('gmaps', 0.4, 2000, True, 'new_n', True);
As a result, we get a new dataset named new_d_add_noise, which consists of the initial points, plus 40% (3) more points, as described above. If we run the following querie we get the new trajectory segments:
SELECT * FROM new_n_add_noise_seg;
Segments of noise gmaps dataset
Additionally, due to csv_file parameter being True, we get a cvs file in the data folder. The name of the file would be gmaps_transformed_addnoise_0.4_2000.txt. Generally, the name of the csv file will be dataset + _transformed + _kind of transformation + _parameters
If we load the initial and the transformed datasets in Google Maps (from the csv files), we get the following result:
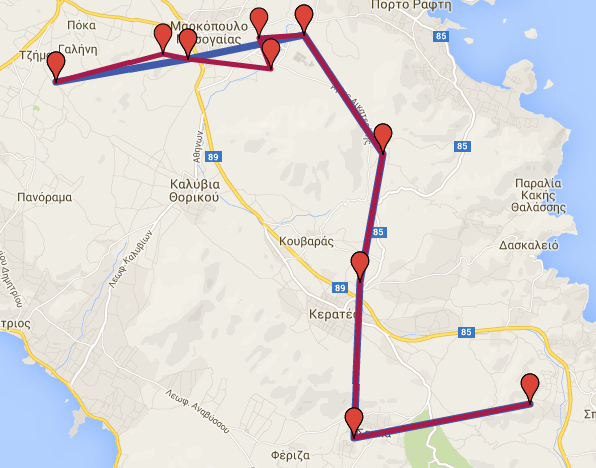
Initial \(blue\) and transformed \(purple\) dataset
Trajectory Synced Shift Transformation
trajectory_transformation_synced_shift (dataset, rate, distance, [save], [new_dataset_name], [csv_file])
Returns
The integer 1 to indicate that everything went right.
Parameters Description
- dataset Text, the name with which the dataset is stored in Hermes.
- rate Float between 0 and 1, number of points to be shifted (rate * |points|).
- distance Integer, shifted point - trajectory point maximum distance, in meters.
- save (Optional) Boolean, indicates whether the new dataset will be saved in Hermes or not. If left blank, the new dataset will be saved.
- new_dataset_name (Optional) Text, If save is True, the name of the new dataset inside Hermes. If left blank, the name of the new_dataset will be transformed_synced_shift
- csv_file (Optional) Boolean, Indicates whether the new dataset will be exported to a csv file, with the default format of Hermes. If left blank, the dataset will be exported to a csv file.
Example
For example purposes, suppose we have a dataset, saved in Hermes, containing one trajectory. The name of the dataset is gmaps. The segments of the dataset are shown below.
Segments of gmaps dataset
It is clear that the trajectory consists of 7 ST Points. If we wanted to shift 90% of the trajectory points, by the same direction and distance (distance at most 1500 meters) we could run the following querie:
SELECT trajectory_transformation_synced_shift('gmaps', 0.9, 1500, True, 'new_s', True);
As a result, we get a new dataset named new_s_synced_shift, which consists of the initial points, 90% of them shifted by the same direction and offset. By running the following querie we can see the new trajectory segments.
SELECT * FROM new_s_synced_shift_seg;
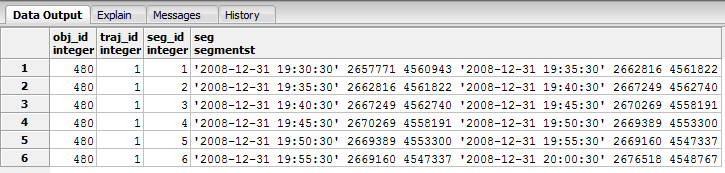
Segments of synced shift gmaps dataset
Additionally, due to csv_file parameter being True, we get a cvs file in the data folder. The name of the file would be gmaps_transformed_syncedshift_0.9_1500.txt. Generally, the name of the csv file will be dataset + _transformed + _kind of transformation + _parameters
If we load the initial and the transformed datasets in Google Maps (from the csv files), we get the following result:
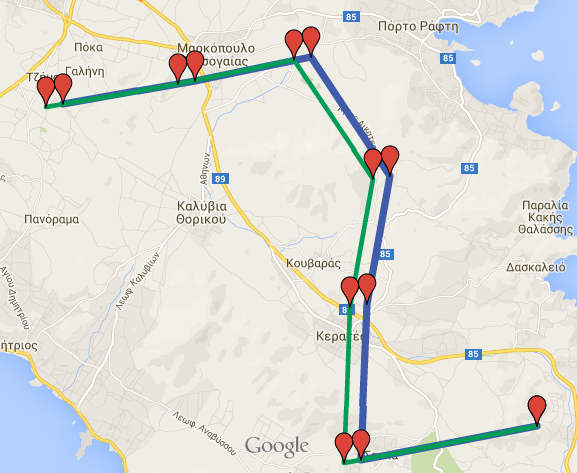
Initial \(blue\) and transformed \(green\) dataset
Trajectory Random Shift Transformation
trajectory_transformation_random_shift (dataset, rate, distance, [save], [new_dataset_name], [csv_file])
Returns
The integer 1 to indicate that everything went right.
Parameters Description
- dataset Text, the name with which the dataset is stored in Hermes.
- rate Float between 0 and 1, number of points to be shifted (rate * |points|).
- distance Integer, shifted point - trajectory point maximum distance, in meters.
- save (Optional) Boolean, indicates whether the new dataset will be saved in Hermes or not. If left blank, the new dataset will be saved.
- new_dataset_name (Optional) Text, If save is True, the name of the new dataset inside Hermes. If left blank, the name of the new_dataset will be transformed_random_shift
- csv_file (Optional) Boolean, Indicates whether the new dataset will be exported to a csv file, with the default format of Hermes. If left blank, the dataset will be exported to a csv file.
Example
For example purposes, suppose we have a dataset, saved in Hermes, containing one trajectory. The name of the dataset is gmaps. The segments of the dataset are shown below.
Segments of gmaps dataset
It is clear that the trajectory consists of 7 ST Points. If we wanted to shift 60% of the trajectory points, by random direction and distance (distance at most 1500 meters) we could run the following querie:
SELECT trajectory_transformation_random_shift('gmaps', 0.6, 1500, True, 'new_r', True);
As a result, we get a new dataset named new_r_random_shift, which consists of the initial points, 60% of them shifted by random direction and offset each. By running the following querie we can see the new trajectory segments.
SELECT * FROM new_r_random_shift_seg;
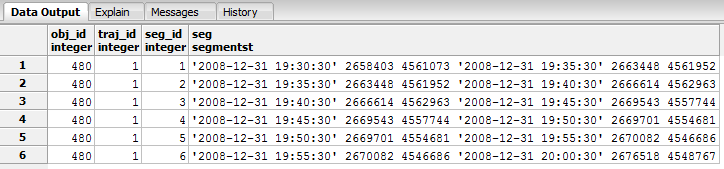
Segments of random shift gmaps dataset
Additionally, due to csv_file parameter being True, we get a cvs file in the data folder. The name of the file would be gmaps_transformed_randomshift_0.6_1500.txt. Generally, the name of the csv file will be dataset + _transformed + _kind of transformation + _parameters
If we load the initial and the transformed datasets in Google Maps (from the csv files), we get the following result:
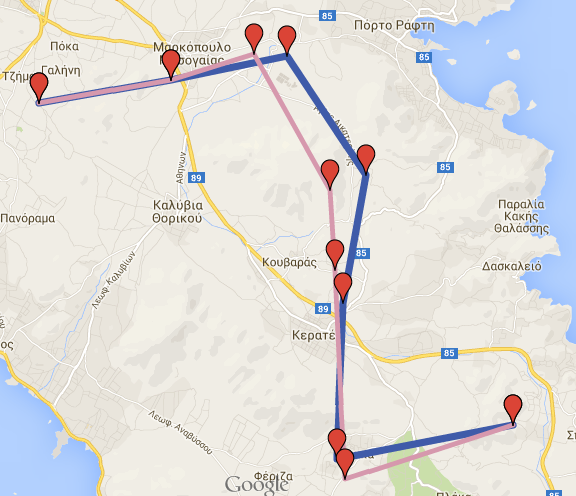
Initial \(blue\) and transformed \(pink\) dataset
latex random.png "Initial \(blue\) and transformed \(pink\) dataset" width=
develop
 1.8.8
1.8.8 
