
PatternMiner v.2
Abstract: The PatternMiner v.2 is an Integrated Pattern Based Management System that is orientated to store and efficiently manage data mining results (patterns) by comparing and monitoring them over time. It is the result of the expansion and the integration of two systems, the Pattern Based Management System (PBMS) PatternMiner v.1 and the Pattern Comparison Framework PANDA (Patterns for Next generation Database systems). The PatternMiner v.1 has the ability to generate data mining patterns, convert them to a uniform PMML form and store them into an XML pattern-base, from which the patterns could be retrieved using appropriate queries. On the other hand, the PANDA framework is a comparison system of both simple and complex patterns of the same type and has the ability to compare many different pattern types.
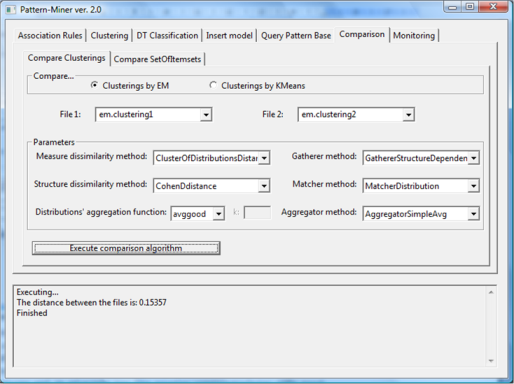
Firstly, the PANDA framework was expanded to include an algorithm for comparing clusterings derived from the data mining algorithm EM. In order to compare this kind of pattern type through the PANDA framework, patterns had to be transformed according to the system theoretical model and then all the appropriate comparison functions for this pattern type were implemented. Thereafter, the PatternMiner v.1 and the PANDA framework were integrated so that the PBMS user is capable of comparing the stored patterns with one of the available algorithms of the Pattern Comparison Framework. Finally, the MONIC+ algorithm for monitoring clusterings over time was incorporated to the PBMS. The MONIC+ algorithm is based on cluster "matching" in order to detect changes in the content and form of a cluster (internal transition) as well as in the cluster relation to the rest of the clustering (external transition). To detect cluster transitions, the cluster overlap - similarity needs to be defined and thus the comparison algorithms of the PANDA framework are used. The algorithm results are presented to the PBMS user both in form of a graph and an XML file.
Thesis: Rampaouni MSc Thesis (in greek)
Screenshots:
Comparing Clusterings of Distributions (patterns generated by EM)
Monitoring 3 Clusterings Centroids (patterns generated by K-Means)
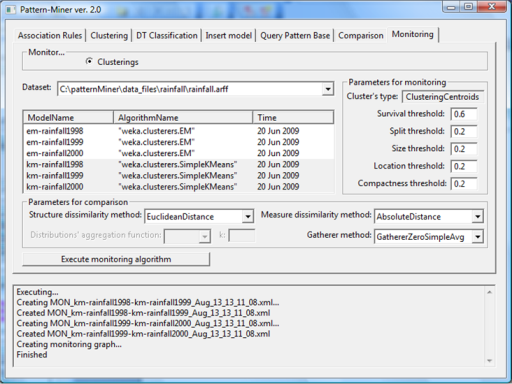
Graph of monitoring results

Datasets:
Collection of images: This dataset contains 10 arff files that come from radiographic images. Each image has been divided into blocks and for each block, a set of 32 features is calculated. Some of possible features may be color, texture and shape.
Collection of images by Image Retrieval in Medical Application (IRMA) group, Dept. of Medical Informatics, RWTHAachen, Germany, https://irma-project.org)
Collection of rainfall data: This dataset contains 4 arff files that come from rainfall data from 113 regions of 2 Greek water districts, Epirus and Eastern Sterea. For each region has been measured the monthly average volume of rainfall during a hydrological year (from October of a year until September of the next year). The arff files refer to hydrological years 1997, 1998, 1999 and 2000.
Collection of rainfall data by Ministry of Development (2006) Water and Natural Resources Directorate, "Water Resources Management Plans on the Water District Scale" Sub-Project: Development of Systems and Tools for the Management of Water Resources in the Water Districts of Central Greece" (West & East Sterea Ellada, Hepiros, Thessaly, Attiki)
Publications: -
People involved: Dimitra Rampaouni